The function of a synchronizer is to translate authoritative abstract state contained in a service’s data models into the concrete operational state of the backend system that implements the service. This document gives a brief overview of the design of a Synchronizer, while also describing other related components in the system, with the goal of framing the architecture of XOS from a mechanistic perspective. A companion document shows how to Implement a Synchronizer.
Design
Synchronizers are designed to realize the core principles of XOS in a robust and efficient way. Most importantly, each synchronizer acts as the link between the data model and the functional half of the system. The data model contains a clean, abstract and declarative representation of the system curated by service developers and operators. This representation is not subject to the idiosyncrasies of distributed system behavior. It defines the authoritative state of the system. The functional half of the system, on the other hand, consists of the software that implements services along with the resources on which they run. Unlike the data model, its configuration is error-prone, liable to reach anomalous states, and involves mechanisms whose implementation and management sometimes do not follow best practices.
A Synchronizer bridges these two sides of the system robustly through the use of an approach we call “goal-oriented synchronization.” Rather than tracking and relaying changes from the data model to the back-end system in the form of events, a synchronizer tracks and drives the system towards a final “goal state” corresponding to the current state defined by the data model. And it does so irrespective of the particular combination of changes that led to that state. As a consequence, an opportunity is made available at every step of synchronization to correct for anomalies created by prior steps, or ones that arise due to ambient system activity.
The specific method we use to accomplish this property is to require synchronization actions to be idempotent. This requirement boils down to two constraints on the implementation of a synchronizer. The first is for a synchronizer to compute a delta between the current and desired state of the service component it manages, and to then apply that delta. The second is to ensure that changes can never propagate back from the synchronizer to the data model in a way that affects the synchronizer’s behavior. Of these, the first requirement is a burden on the service developer who implements a particular synchronizer, and the second requirement is fulfilled by the synchronizer core, which all service synchronizers share. The specific details of how the flow of details is kept unidirectional are provided in detail in later sections. For now, we will introduce the actors in a synchronizer that interact with the data model.
Actors and Types of State
There are three actors in a Synchronizer that interact with a Data Model: Synchronizer Actuators, Synchronizer Watchers, and Model Policies. Actuators are notified of changes to the data model, upon which they refer to the current state of their service in the data model, and idempotently translate it into a configuration for their service. A given data model can only have one actuator, scheduled by the synchronizer core in an ordering consistent with the dependencies on the model that it synchronizes, with possible retries and error management. Watchers are also notified of changes to a data model, with the difference that they are not responsible for actuating its state by applying it to the system substrate. A Watcher for a given model is an actuator for a different model (i.e., not the one it watches). It subscribes to the watched model to gather information that it needs in addition to the data model that it synchronizes. For example, a synchronizer for a daemon may watch the IP address of the host it runs on, not because it configures the host with the IP address, but because it needs to advertise its address to clients that use the daemon. A model policy encapsulates data relationships between related data models, such as “for every Network there must be at least one interface.” Concretely in this example, a model policy would intercept creations of Network models and create Interface models accordingly.
The Data Model represents the authoritative and abstract state of the system. By authoritative, we mean that if there is a conflict, then it is given precedence over the internal configuration of services. This state is a combination of two types of fields: Declarative and Feedback. Declarative state is sufficient to recreate the full operational state of the system, with the help of a particular synchronizer. Feedback state is derivative. It is the result of Synchronizer actions, preserved as a cache for later accesses to the backend objects created as a consequence of those actions. Synchronizers are mainly interested in declarative state, as that is the basis on which they configure the service they implement. The core synchronizer machinery ensures that synchronizers are notified of changes to declarative state, that they are invoked in an appropriate order, and also provide a degree of resilience to failure.
The actors of a synchronizer interact with this state in the following manner:
Actuators can:
Read Declarative state
Read/Write Feedback state
Be scheduled upon changes to Declarative state
- Watchers can:
Read Declarative state
Read Feedback state
Subscribe to changes to Declarative state (meaning no dependency ordering, no retries, no error propagation)
Model Policies can
Read/Write Declarative state
Subscribe to changes to Declarative state
The following example shows two synchronizers (SyncInterface and SyncFileServer) both actuating/synchronizing and watching three models (Host, Interface, and FileServer).
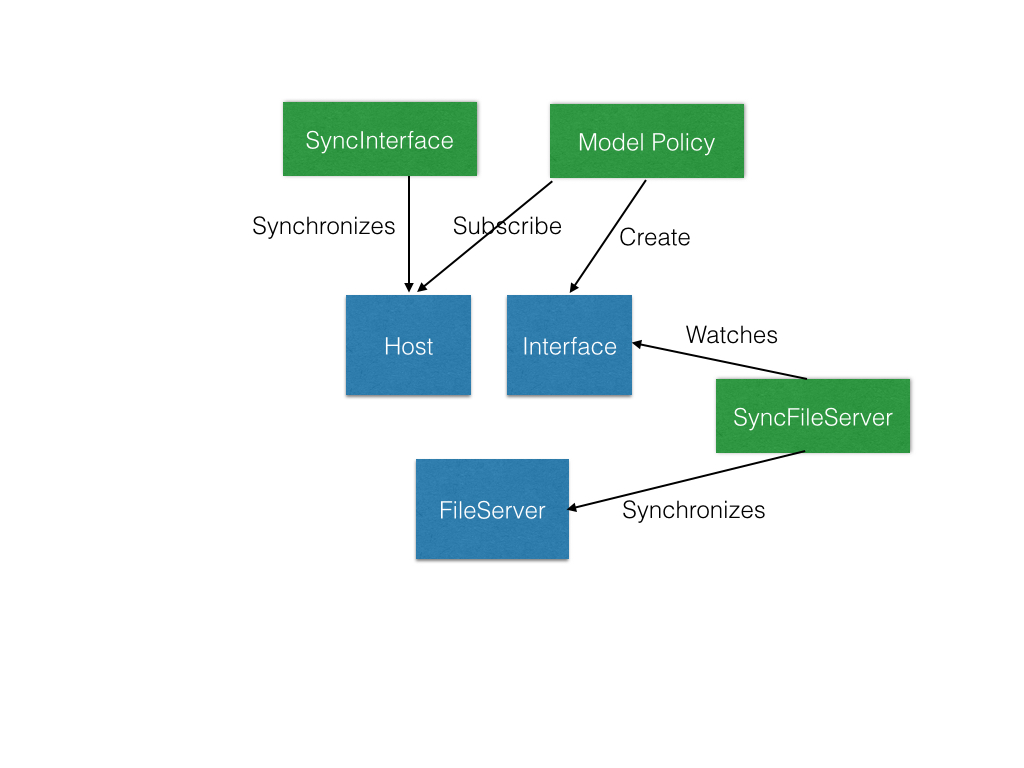
Relationships Between Synchronizers and Data Models
A single synchronizer can synchronize multiple data models, usually through an actuator per model. However, a given model can only be handled by one actuator. Furthermore, a single actuator only synchronizes one data model. The act of synchronizing may generate feedback state in the same model, but watching never generates/modifies feedback state in the model being watched. (Watching model A may be part of synchronizing mode B, and so generates feedback state in B.)
But how are these relationships established? The answer lies in the linkages between models in the data model. The data model, which is implemented using Django, lets us link one model to another through references called foreign keys and many-to-many keys. Apart from enabling organizational patterns such as aggregation, composition, proxies, etc. this linkage is used to establish two levels of dependencies: ones between models, and ones between objects. If a field interface in a model for a daemon references an Interface model, then it implies that the daemon’s model depends on interface. Furthermore, that an object of type daemon depends on an object of type interface if the interface field of the latter contains a reference to the latter.
Dependencies between models can be specified in two ways:
Implicitly through linkages in the data model
Explicitly through annotations, which are in turn read by the synchronizer core
Once these dependencies have been extracted, they decide whether synchronizer modules are actuators or they are watchers. They also configure the scheduling of actuators in a way that they are run in dependency order, and so that errors in the execution of an actuator are propagated to its dependencies. Consider the diagram below.
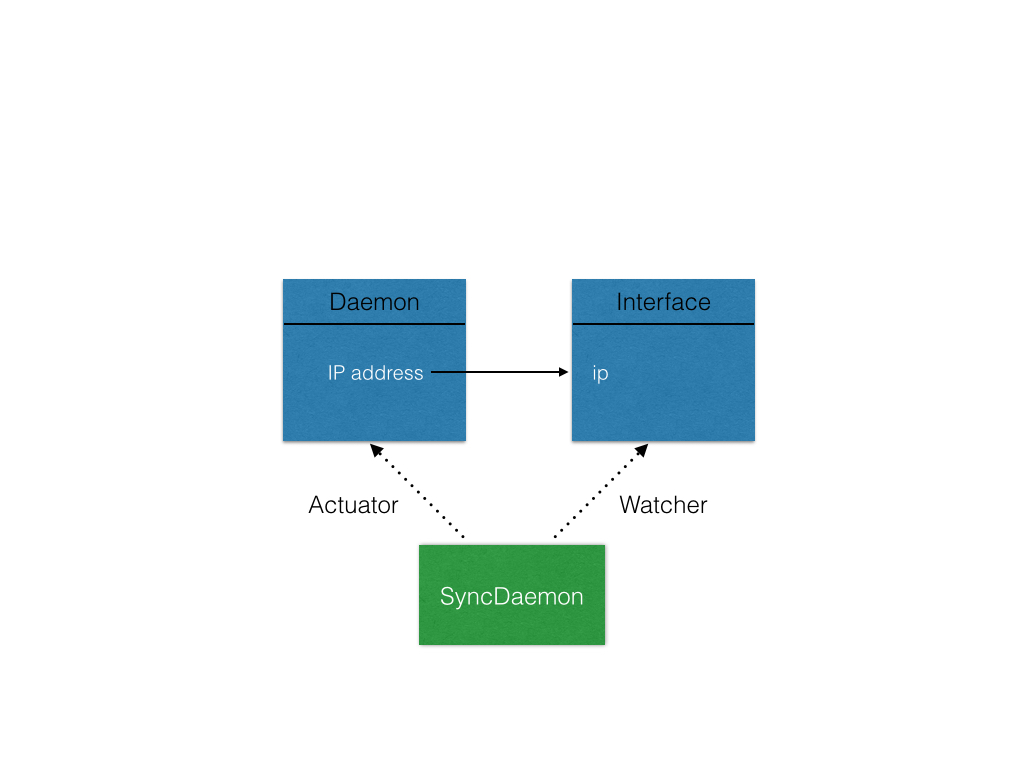
Here, the Synchronizer action SyncDaemon actuates the daemon model (this information is contained in the model’s metadata, which specifies the name of its Synchronizer). But in doing so, it also needs the IP address of the interface to which the daemon is bound, which is contained in the Interface model. We say that the Interface model is at a distance of “1” from the SyncDaemon action, while the Daemon model is at a distance of 0. An action can opt to watch, actuate, or ignore changes in a given model by specifying thresholds of distance. By default, models at a distance of 0 are actuated, and ones at a distance of 1 are watched.
Loops
The separation of declarative and feedback state in the data model eliminates the possibility of loops involving actions, caused by a synchronizer directly modifying its declarative state. Such loops involve repeated executions of one or more actions by the synchronizer core. But it does not eliminate loops of the following kind
Loops caused because a synchronizer modifies declarative state indirectly - say by triggering an external action that modifies the state via the API.
Loops in which feedback state written by one Synchronizer is watched (read) by a second Synchronizer, and feedback state written by the second Synchronizer is watched (read) by the first Synchronizer. Of course, this type of interference can also happen across a chain of Synchronizers. These loops can be detected by analyzing the synchronizer-watcher-model graph.
Spin loops and other general loops found in programs.
The second possibility is unlikely in practice because it would be akin to a data model version of a layering violation: Layer i depends on Layer i+1, while at the same time Layer i+1 would depend on Layer i.
Dependencies and Data Consistency
XOS enforces sequential consistency, without real-time bounds. This is to say that no guarantees are made on when the goal state will be transferred from the data model to the back end, but it is guaranteed that the components of the states defined by individual data models will be actuated in a valid order. This order is implied by the dependencies described in the previous section. For example, if a host model depends on an interface model, then it is guaranteed that the actuator of a host will execute only when the actuator of the corresponding interface has completed successfully. Note that this sequencing guarantee does not apply to watchers. The watchers for a model are executed in an arbitrary order.
Outside of the ordering mandated by dependencies in the data model, operations may be rearranged randomly, or to favor the concurrent scheduling of actuators. This property poses an important task for a service designer, making it necessary for him to specify all ordering constraints comprehensively in the service data model. If any orderings are missed, then even if changes to a set of models are properly ordered at the source, their actuation may be reordered into sequences that are invalid.
Error Handling and Idempotence
The synchronizer is designed to be robust to unforeseeable faults in the back-end system. The main source of this robustness is the idempotence of actuators. Rather than blindly executing an operation on the current state, actuators target a goal state. This means that they are expected to make a reasonable effort to compensate for anomalies. Goal-directed synchronization, i.e., the strategy of driving towards the end state, rather than simply “replaying” events is central to this outcome. In the latter case, actuators would have no other choice than to dutifully apply incoming updates, even if the start state is anomalous, and likely lead to an anomalous end state.
A synchronizer tries to schedule as many actuators as it can concurrently without violating dependencies. Dependencies are tracked at the object level. For example, in the example mentioned previously, the failure of the synchronization of an interface would hold up a host if the interface is bound to it, but not if that interface is bound to a different node. When there is a failure, the synchronizer core re-executes the actuator at a later time, and then again at increasing intervals.